
Table of Contents
- 79% of top news sites block AI training bots via robots.txt.
- Google-Extended is the least blocked among training bots.
- 71% of sites also block AI retrieval bots.
- PerplexityBot, used for indexing, is blocked by 67%.
- Only 14% of publishers block all AI bots, while 18% don’t block any.
- Bots can circumvent robots.txt directives.
Everyone wants to show up in AI.
And in the digital marketing realm, everyone is flocking to digital PR in hopes of getting their brands mentioned in citations.
However, there is a vocal majority of publishers (and their journalists, especially) who are very vocally anti-AI.
Some, such as the New York Times, are actively suing AI companies for using their data.
But are the publishers blocking it from showing up in AI results, or from using the data to train their models?
When you examine the data, specifically the robots.txt files, you begin to see a clearer picture of how publishers are handling AI crawling of their sites.
In this post, I analyzed the robots.txt files of 100 top news sites in the US and UK to determine who is blocking AI—and more importantly, what it means for digital PR.
(I credit the Screaming Frog team for giving me the idea for this piece. They analyzed UK sites back in July 2025.)
Methodology
We examined the top 50 in the UK and the top 50 in the US, based on SimilarWeb traffic share, for a combined total of 100. We then deduplicated the list to produce the final list used for the calculations presented in this study.
Background on AI Bots, Robots.txt, and Crawlers
If you are unfamiliar with robots.txt, crawlers, and related concepts, here is a brief primer to get you up to speed. If you know all of that stuff, skip to the takeaways!
What is a Robots.txt File?
Robotic spiders crawl the World Wide Web. Some crawlers, such as Googlebot, are used to gather and index information for use in Google search results.
Robots.txt files instruct crawlers how to interact with a site.
You can restrict crawlers from indexing certain areas of the web, such as a staging site, by using the “Disallow” directive.

So, that’s what we are looking for in our study.
What AI Crawlers Are We Looking For in This Study?
In our study, we examined robots.txt files for disallow directives used by 11 AI-related crawlers.
A crawler is software that fetches pages, while a bot is the agent that interacts with the site. If that’s confusing, it’s not super important; what’s important is how and what they do.
Some crawlers are used for training, whereas others perform more active retrieval. The same company can have multiple crawlers that perform different tasks.
Blocking Training Data vs Indexing vs Retrieval
When publishers say “blocking AI,” they usually mean training data, not indexing for search. But there’s also retrieval, which I feel is a bit of a muddy area.
Blocking training data prevents a site’s content from being used to train the AI models.
For instance, GPTBot is used to gather training data for ChatGPT.
Blocking retrieval bots prevents the site from appearing when an AI tool attempts to retrieve live data (either for grounding or when a user requests citations).
For instance, if you ask Gemini something that it doesn’t have in its corpus of information, it will effectively do a Google search to confirm its answer is correct.
Blocking indexing prevents the site from appearing in search results.
For instance, PerplexityBot indexes pages to pre-build Perplexity’s answer corpus.
This is different than GPTBot, which focuses on training data, or ChatGPT-User, which handles live retrieval queries from users.
So, the breakdown of the crawlers we are looking at is:
| Category | Bots |
|---|---|
| Training | GPTBot, ClaudeBot, Anthropic-ai, CCBot, Applebot-Extended, Google-Extended |
| Retrieval / Live Search | ChatGPT-User, Claude-Web, Perplexity-User, OAI-SearchBot |
| Search Indexing | PerplexityBot |
With that out of the way, here are the findings.
Here is a list of the top 50 news sites and the crawlers they block:
Top 50 News Sites and the AI Crawlers They Block
This list of news sites is based on SimilarWeb data.
For the sake of space, I’ve grouped them by the kind of AIcrawler they are involved in: training, retrieval, and indexing.
| Traffic Rank | Domain | Blocks Training | Blocks Retrieval | Blocks Indexing* |
|---|---|---|---|---|
| 1 | bbc.co.uk | Yes | Yes | Yes |
| 2 | yahoo.com | Yes | Partial | No |
| 3 | theguardian.com | Yes | No | No |
| 4 | nytimes.com | Yes | Yes | Yes |
| 5 | dailymail.co.uk | Yes | Yes | Yes |
| 6 | cnn.com | Yes | Partial | Yes |
| 7 | foxnews.com | No | No | No |
| 8 | bbc.com | Yes | Yes | Yes |
| 9 | msn.com | Yes | Partial | Yes |
| 10 | telegraph.co.uk | Yes | Yes | Yes |
| 11 | thesun.co.uk | Yes | Partial | Yes |
| 12 | independent.co.uk | No | No | No |
| 13 | people.com | Yes | Yes | No |
| 14 | finance.yahoo.com | Yes | Partial | No |
| 15 | news.sky.com | Yes | Yes | Yes |
| 16 | express.co.uk | Yes | Partial | No |
| 17 | usatoday.com | Yes | Partial | No |
| 18 | mirror.co.uk | Yes | Partial | No |
| 19 | apnews.com | Yes | Yes | Yes |
| 20 | nypost.com | Yes | Yes | Yes |
| 21 | news.google.com | Yes | No | No |
| 22 | cnbc.com | Yes | Partial | No |
| 23 | gbnews.com | No | No | No |
| 24 | mumsnet.com | Partial | No | No |
| 25 | dailyrecord.co.uk | Yes | Partial | No |
To view the complete list of top 50 overall, as well as the top 50 UK and 50 US sites, broken down in more detail by crawler, check out this Google Sheet.
If all you care about is whether you should contact these sites, jump to the end
Overall Breakdown of AI Crawlers Blocked by News Sites
Here is the breakdown of the percentage of sites that block vs allow specific crawlers associated with AI:
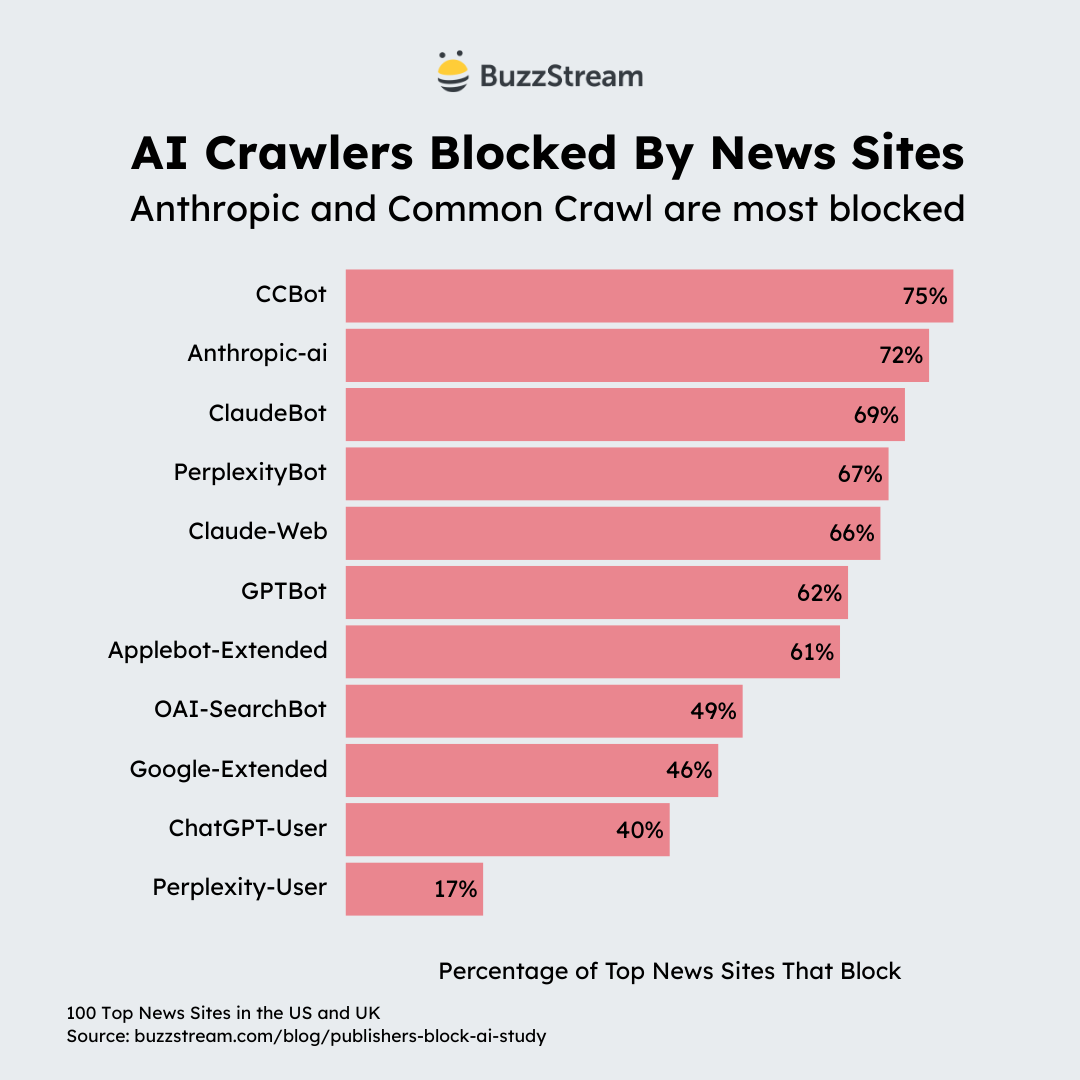
Here is the table:
| Bot Name | Blocked % |
|---|---|
| CCBot (Common Crawl) | 75% |
| Anthropic-ai | 72% |
| ClaudeBot | 69% |
| PerplexityBot | 67% |
| Claude-Web | 66% |
| GPTBot | 62% |
| Applebot-Extended | 61% |
| OAI-SearchBot | 49% |
| Google-Extended | 46% |
| ChatGPT-User | 40% |
| Perplexity-User | 17% |
Let’s dig into these results and what they mean.
79% of Sites Block at Least One Bot Used for Training AI
When we break down the types of bots that gather information for training, we find that, on average, about 80% of sites don’t want their data used for training.

Here is the table:
| Bot | % Blocked | Purpose |
|---|---|---|
| CCBot | 75% | Training data source for many AI models |
| Anthropic-ai | 72% | Training Claude (legacy) |
| ClaudeBot | 69% | Training Claude |
| GPTBot | 62% | Training ChatGPT |
| Applebot-Extended | 61% | Training Apple Intelligence |
| Google-Extended | 46% | Training Gemini |
This tracks with the idea that publishers don’t want AI to use their content without paying for it.
But, to get a more personal take on it, who better to ask than our previous podcast guest and SEO Director at a major UK publisher, The Telegraph, Harry Clarkson-Bennett.
He told me:
“Publishers are blocking AI bots using the robots.txt because there’s almost no value exchange.
LLMs are not designed to send referral traffic and publishers (still!) need traffic to survive.
So most of us block AI bots because these companies are not willing to pay for the content their model has been trained on and their output is almost entirely internal.
So we’re making a stand.
Particularly as they don’t respect pay walls either.”
Making a stand indeed! This push against AI is definitely an ongoing movement in the PR and SEO communities.
But let’s look at the results more closely to see how publishers are making their stand.
Common Crawl is the Most Blocked Bot
If you’re unfamiliar with Common Crawl (CCBot), it is a nonprofit organization that maintains a free online repository of petabytes (1,000 terabytes) of web crawl data.
(If you want to learn more about Common Crawl, I suggest this breakdown from Brett Tabke.)
That said, although it is an independent nonprofit, many early versions of popular AI tools, such as ChatGPT and Google’s BERT, have used Common Crawl to train their models.
Google Gemini’s Training Bot is the Least Blocked
Google-Extended trains Gemini. So, even though it’s not used for Google’s search index, it’s clear that Google still receives preferential treatment from many publishers, regardless of their views.
Harry agreed here:
“I suspect people are a little kinder with Google because there’s a wider value exchange with their wider suite of products.
Equally Gemini came along a little later than others.”
I also think there may be some trepidation about blocking anything related to Google because there’s so much riding on already shrinking organic traffic.
If publishers are concerned about training, do their views on willingness to be featured in live search or retrieval change?
71% of News Sites Block at Least One AI Live Search/Retrieval Bot
Roughly 71% of major news sites also block AI systems from accessing their content during live searches.
Here is the data:
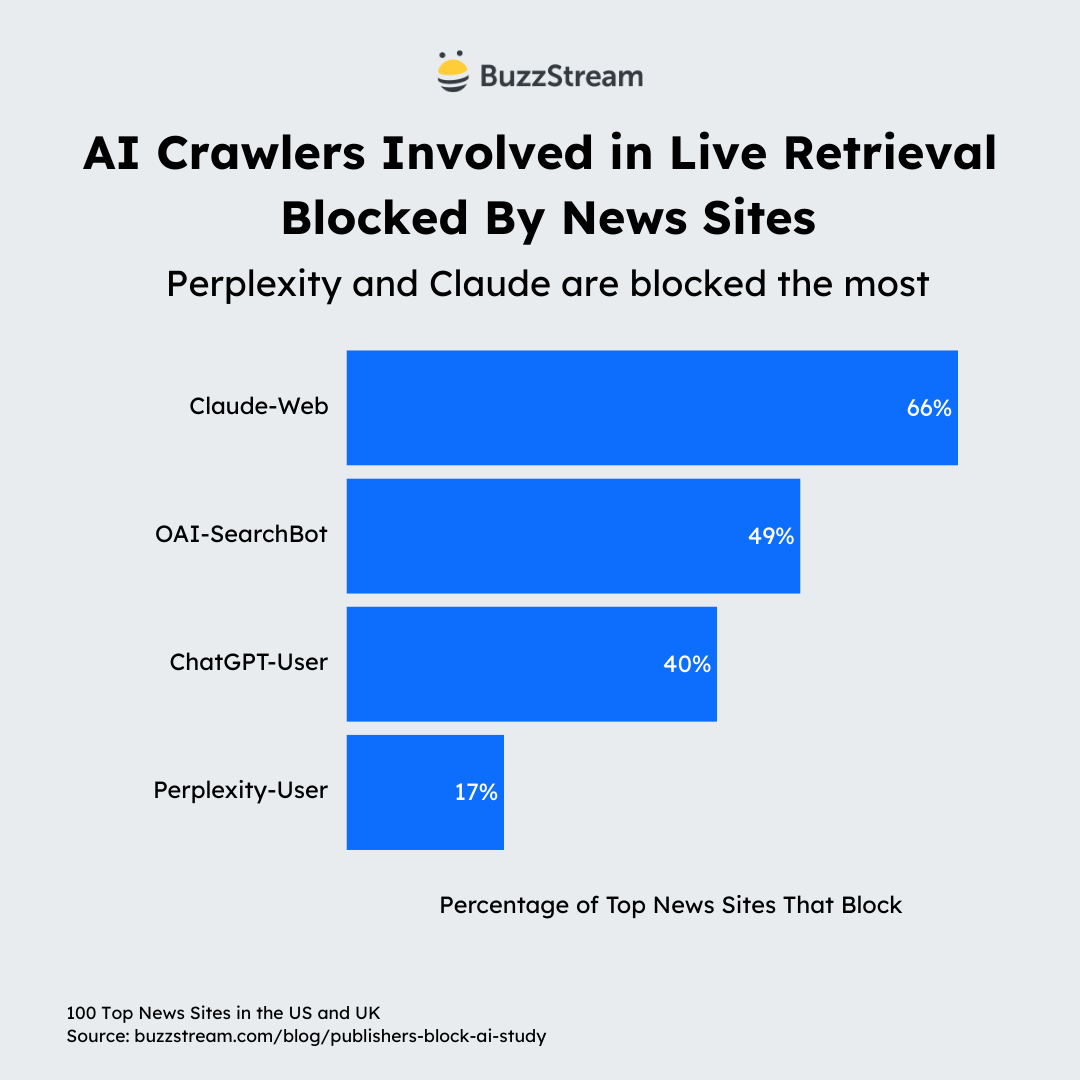
In my opinion, these sites are also missing out on potential referral traffic.
Here’s how it breaks down:
| Bot / Crawler | Company | Primary Purpose | % of Sites Blocking |
|---|---|---|---|
| Claude-Web | Anthropic | Live web retrieval for Claude responses | 66% |
| OAI-SearchBot | OpenAI | Live search used by ChatGPT for current queries | 49% |
| ChatGPT-User | OpenAI | User-initiated fetch (browser-like access triggered by a prompt) | 40% |
| Perplexity-User | Perplexity | User-initiated fetch | 17% |
I initially thought that the sites’ blocking training might enable live retrieval, but in the next section, we’ll see that this isn’t the case.
But roughly 7 in 10 sites block bots involved in both training and live retrieval.
This indicates that the publishers’ stance against AI is firm, even if it entails the risk of losing referral traffic.
67% of Sites Block Perplexity’s Bot Used for Indexing
As the only bot on this list that is involved in indexing, it’s interesting that only 67% of the top news sites block it.
I would think that if you don’t want another tool using your information, you wouldn’t let it crawl your site.
There may, however, be an obvious, somewhat controversial answer to this.
As Perplexity explains, it’s not used to crawl for its foundational model; it is used only to surface and link websites.
Perplexity doesn’t have a training bot. Instead, they used PerplexityBot to scan the web and index information that they can then surface later in their answers—similar to how Google does it with its Googlebot.
There’s some controversy, however, that has put Perplexity in some hot water, and it may explain why more publishers don’t block IT.
The Cloudflare team uncovered that Perplexity has a way to bypass robots.txt.
So, it could be that most publishers don’t think it’s essential to do. (More on the potential ineffectiveness of blocking robots.txt later.)
Only 14% of Sites Block ALL of the AI bots, 18% Don’t Block Any
This is the nuclear option. Just 14% of the sites block everything.
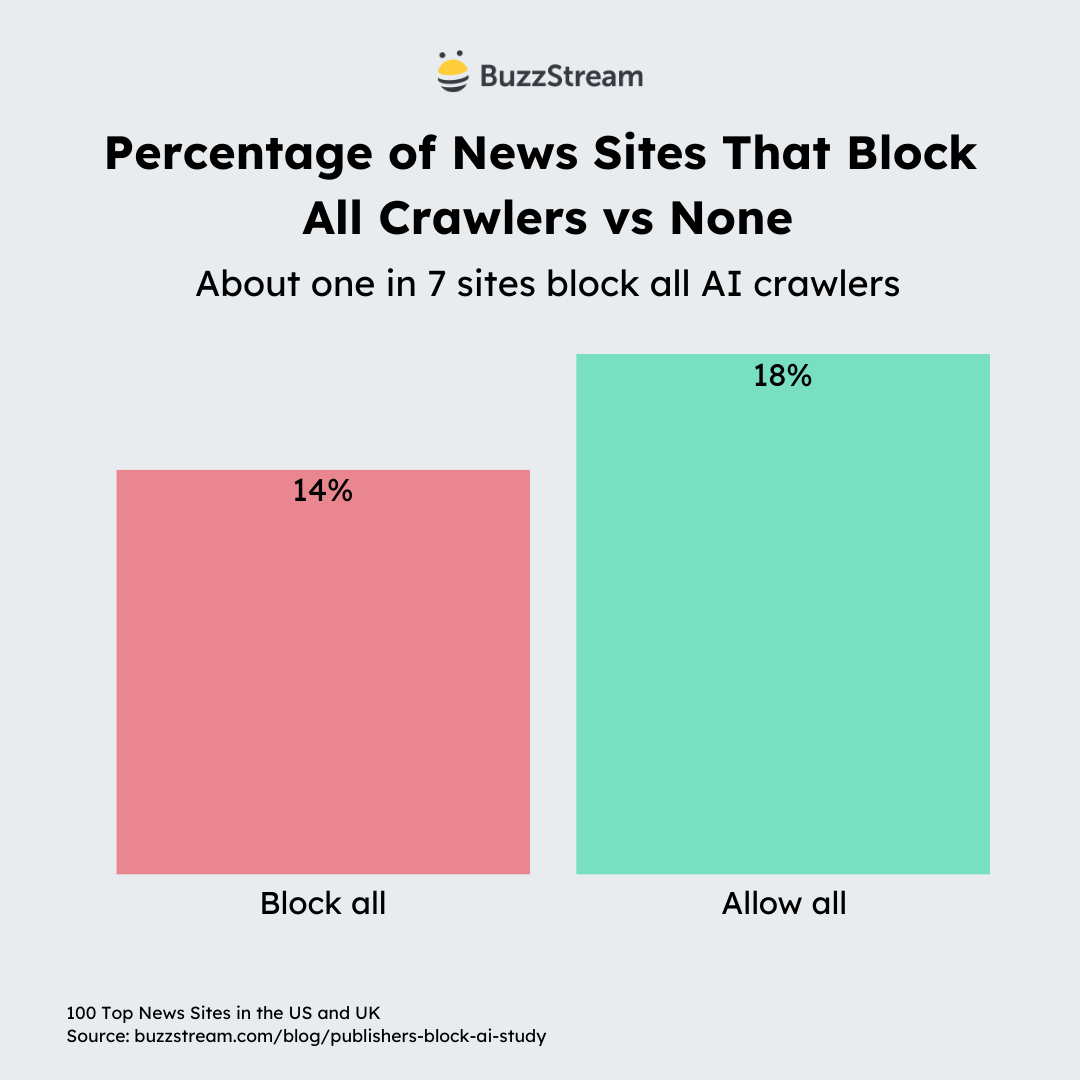
Conversely, a slightly higher number of sites (18%) don’t block any of the bots we covered in our study.
The final point I wish to examine is how UK publishers handle this compared with those in the US.
US Publishers Are More Restrictive Against Google
Overall, when we compare, we can see that both UK and US are fairly restrictive.
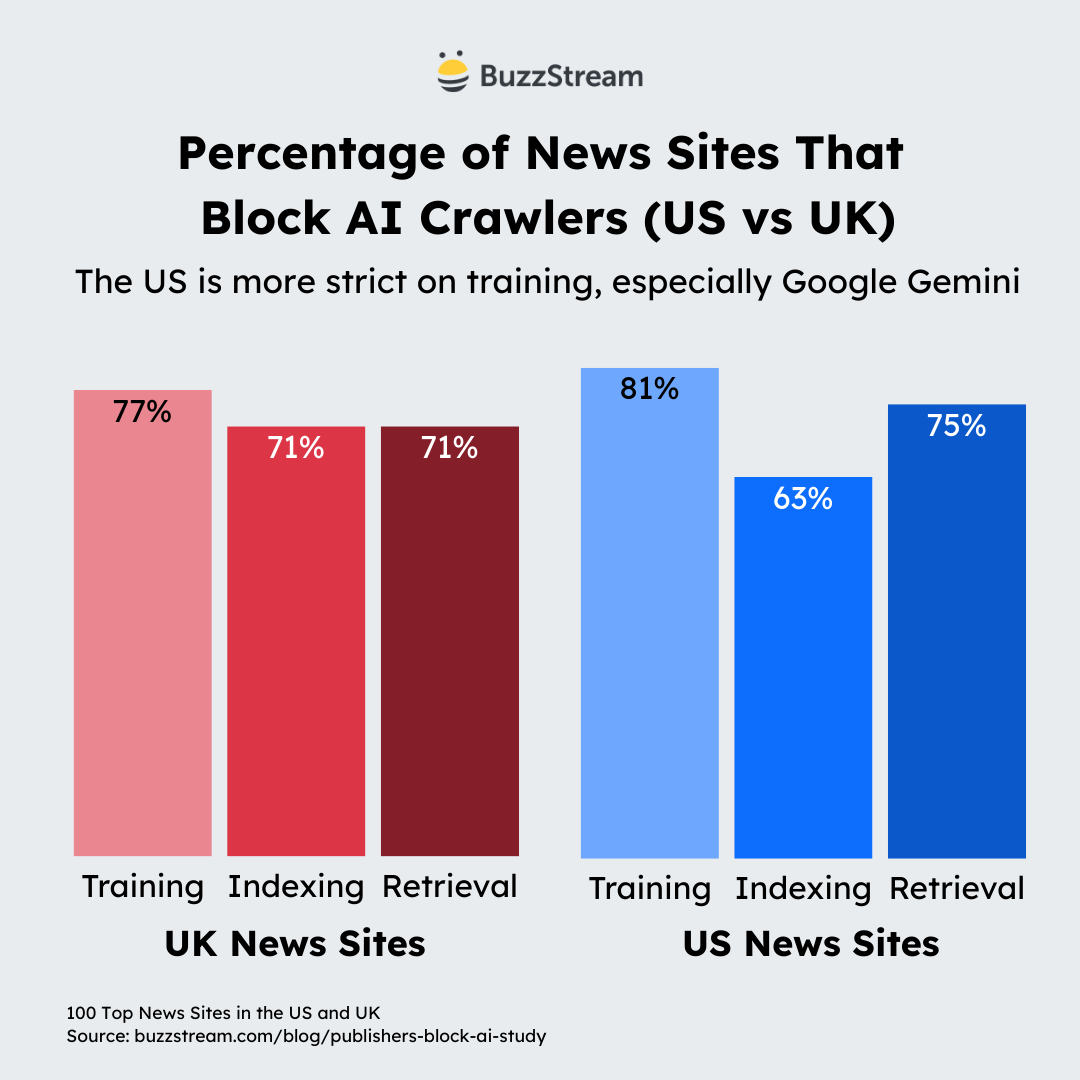
Here’s the table comparison:
| Function | UK Blocked % | US Blocked % |
|---|---|---|
| Training | 77% | 81% |
| Indexing | 71% | 63% |
| Retrieval | 71% | 75% |
However, when you dig deeper, something else comes out.
US Publishers are much more aggressive against blocking Google-Extended (58%) than UK publishers (29%).
Note that Google-Extended is used for training Gemini.
Upon further investigation, it remains unclear why this is the case. There are major US lawsuits against AI, as well as some in the UK.
However, there is one other layer that Harry Clarkson-Bennett added that threw a wrench into this whole study for me: “Worth noting that blocking via the robots.txt (a directive) is almost wholly ineffective and it needs to be done at a CDN level to be effective.”
Robots.txt Files are Directives, not Definites
As we saw with Perplexity, there are some signs that the bots ignore (strategically or not) the robots.txt directives.
“So the robots.txt file is a directive. It’s like a sign that says please keep out, but doesn’t stop a disobedient or maliciously wired robot.
Lots of them flagrantly ignore these directives. This has led to publishers being forced to use things like bot managers to block them at a CDN level. Sometimes at significant expense.
In lots of cases it’s still not enough to just blacklist certain bots because they take circuitous routes. IP rotation, user-agent spoofing, third parties etc.
So technology that identifies and blocks a bot by fingerprinting (it’s digital ID) plays a part too. So you have robots.txt (useful, but ignored), CDN blocking (better) and new bot blocking technologies.
The joy.”
The joy, indeed, Harry.
So what now?
What does this all mean for digital PR?
Should Digital PRs Avoid Sites That Block AI Crawlers?
The short answer is no, don’t avoid sites just because they block crawlers.
For one, it seems like robots.txt files aren’t even effective for this.
Additionally, not all bots block you from appearing in the same way.
- Sites blocking training data can still appear in citations coming from live retrievals
- Sites blocking live retrievals can still show up as citations when pulled from the knowledge base
- Sites that have expressed data partnerships with specific AI systems may appear in either case (we do not yet know much about how that works).
In any case, the hope is that you are sufficiently referenced by high-value sites that the AI tools consider your content or brand worthy of inclusion in their knowledge base.
(Though we still don’t know much about how these models choose what goes into their knowledge base outside of broad statements like “create high authority, high quality content”.)
I would argue that AI citations coming from the knowledge base are “worth” more because they are harder to obtain and longer-lasting.
But remember, AI citations are just one piece of the puzzle. The brands that win are creating compelling narratives and building their brand awareness across multiple platforms.
They are not chasing a link or an AI citation.
They have SEO, PR, and brand teams working together toward the same goal. That’s how you win in 2026.

 Check out the BuzzStream Podcast
Check out the BuzzStream Podcast






